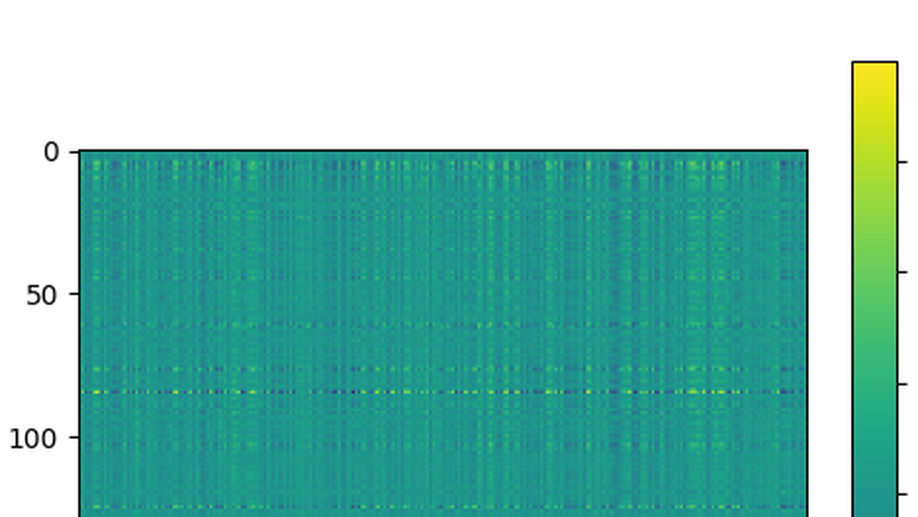
On Difficulties of Attention Factorization through Shared Memory
Our findings challenge the conventional thinking on the models that use external learnable memory, like Luna or Memory Augmented Transformer, to reduce the computational complexity. We reveal that interfacing with the memory directly through an attention operation is suboptimal, and that the models’ performance may be considerably improved by filtering the input signal before communicating with it.
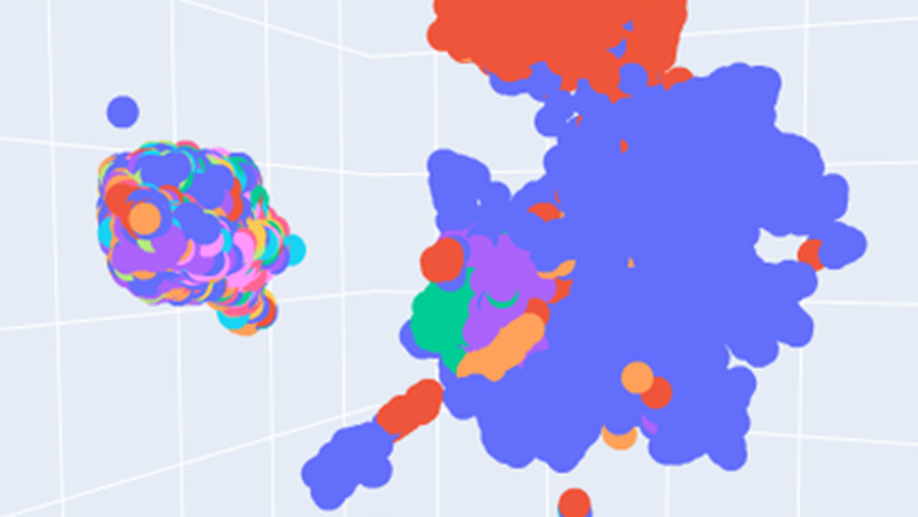
Text-to-Ontology Mapping via Natural Language Processing Models
We have started to automatize the process of an automatic assignment of a relevant ontology to an input article, and attack the problem by utilizing state-of-the-art NLP tools and neural networks. We assess the quality by visializing the latent space of annotation and text embeddings and sampling examples of mappings between text fragments and ontology annotations.

Linear Self-Attention Approximation via Trainable Feedforward Kernel
We employ the kernelized formulation of an attention computation in Transformer, and evaluate the kernel implementation as FFNN on the subset of the Long Range Arena.
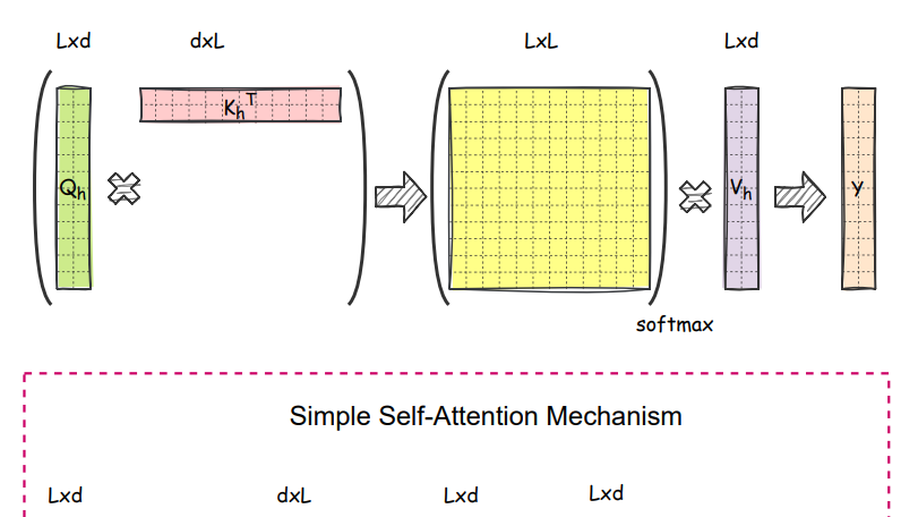
SimpleTRON: Simple Transformer with O(N) Complexity
We have suggested, that a Transformer attention module can be implemented without a nonlinearity between query and key multiplication, and evaluated our findings on the Long Range Arena subset.